Self-Assessment
Hello, my name is Onur Vallor. I have been attending Southern New Hampshire University's (SNHU) Computer Science program for the past two years. During those two years, I have developed a great foundation in software engineering, algorithm problem solving, databases and security. This ePortfolio will highlight both my academic growth and growth as a software engineer. By enhancing two artifacts, I will showcase my technical expertise and readiness to enter the industry as a professional.
Through personal projects and coursework, I have learned to effectively collaborate in order to accelerate and improve the quality of projects. Writing thorough commits, readme and other documentation, I am able to communicate with other developers and peers. This ePortfolio's code review showcases my ability to professionally communicate complex and technical topics into clear and concise explanations for both developers and non-technical individuals.
In software design and engineering, I gained practical, real-world experience by turning a concept into a functional piece of code in an existing system. The "3D OpenGL Scene" artifact added an object loader, debugged segmentation faults, fixed dependencies and created a Make file for scalable compilation. All these enhancements taught me how to deliver production quality software and use well-founded and innovative techniques that deliver value and meet industry goals.
In algorithms and data structures, I enhanced the "Grazioso Salvare Search-And-Rescue Dashboard" artifact by optimizing data retrieval and manipulation. By implementing a compound index, server-side aggregation, and flexible CRUD operations, I improved performance and efficiency. These enhancements demonstrate my ability to design and evaluate computing solutions using algorithmic principles and computer science practices.
In databases, I improved the same "Grazioso Salvare Search-And-Rescue Dashboard" artifact by enhancing database security and performance. Moving credentials to environment variables, implementing SHA-256 authentication, and optimizing queries with a compound index showcase my ability to manage and optimize databases effectively. These changes align with industry best practices and demonstrate my readiness to handle real-world database challenges.
Security is a very important part of the DevSecOps cycles. It is integrated in every step. Previous coursework as well as improving the security of my artifacts taught me many things such as anticipating potential threats. By replacing hardcoded credential values with environment variables and using SCRAM-SHA-256 for authentication I have ensured the integrity of the data in my artifact. Exposing these potential vulnerabilities, mitigating design flaws and ensuring the integrity of data and resources allow me to be ready for industry projects.
Artifacts
Code Review
Software Design and Engineering
The artifact is an OpenGL 3D scene. It was created for a previous course called Computer Graphics and Visualization (CS330). I chose to include this artifact in my ePortfolio because I felt as though this was something that differed greatly from other courses and projects completed. It has many moving parts that I am not too familiar with which make it challenging but fulfilling once everything gets sorted out. The artifact was improved by adding an OBJ file loader. An OBJ file is a file with information on vertices, normals, uvs and faces. Using this information we can create a function that can read this information and parse it into a format OpenGL will understand. From there we are able to render the object to our scene.
The outcomes planned to be met with this enhancement was to design and evaluate computing solutions that solve a given problem using algorithmic principles and computer science practices and standards appropriate to its solution and demonstrate an ability to use well-founded and innovative techniques, skills and tools in computing practices for the purpose of implementing computer solutions that deliver value and accomplish industry-specific goals. I believe these outcomes have been met for this artifact enhancement. Using well-founded techniques, I was able to implement an OBJ file loader by parsing the file format and then using the data extracted to render the object onto an OpenGL scene. This is a well known technique to create an object in a 3D design program like Blender and easily import it into an OpenGL scene without having to hardcode each vertex, uv, normal and face of the object. This also ties into outcome 3. Using this technique I was able to solve the issue of not being able to use more complex objects in the scene.
The biggest challenge I faced while working on this artifact was getting it to run on my Ubuntu laptop. Originally this artifact ran on Codio Windows computer. After I pulled the files from GitHub certain files and libraries were missing. Then, I came across many segmentation faults. I wrote many debug print statements to see where the segmentation faults were occurring and was able to narrow down and solve the issues one by one. This took by far the longest amount of time but it improved my skill of sniffing out issues through the debug process. It also taught me to push all my project files to GitHub so it will work with little tweaking. I also learned quite a bit about how to extract and parse data in a format that OpenGL can understand.


Algorithms and Data Structures
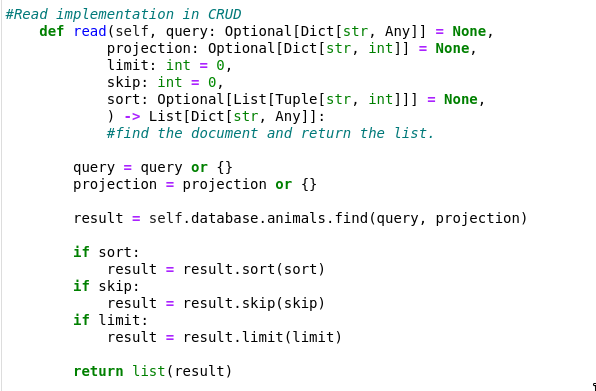
The artifact I selected for this enhancement in algorithms and data structures is “Grazioso Salvare Search-And-Rescue Dashboard” for the course CS-340 Client/Server Development. It is a dashboard created to aggregate data provided by nearby animal shelters in the Austin, TX area and display the information in a way for users to find suitable dogs for search and rescue training. This artifact relies heavily on how data is stored, formatted and utilized. In many scenarios data will be provided as a CSV file or something similar, where many entries need to not only be stored but also displayed in an efficient manner. How this data is manipulated and sorted has a great impact on performance and usability. The larger the pool data becomes, the more important data structures and algorithms become to handle it. There are a few key areas I changed to enhance this artifact. I created a compound index which takes certain columns that are frequently searched for and builds an index on them. This compound index greatly reduces the redundancy of full document scans to our MongoDB making retrieving data much more lean. Similarly, creating a table projection of only columns we want to be displayed on the table for the user reduces the document size retrieved and renders faster. There have also been a handful of enhancements made to the algorithms in this artifact as well. Within the CRUD python file, I have enhanced the functionality of the read function by adding arguments for projection, limit, skip and sort. These additions port to what MongoDB can handle. Previously, the pie chart would gather information and have python do the heavy lifting for the aggregation. By using server-side aggregation the work is off-loaded to MongoDB.
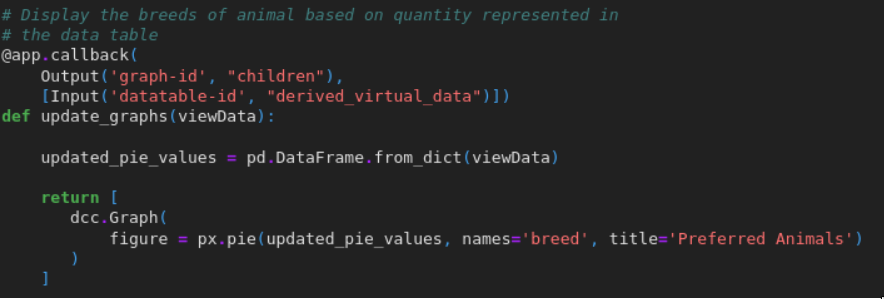
The biggest challenge I faced was knowing what to improve and what can be improved. I have a sense of what might be able to be enhanced but you do not know what you do not know. With that being said, an important lesson I learned is to research what others have done and how they implemented innovative methods to enhance the areas I am looking to do the same with. That took some digging because someone might say how they enhanced a certain feature of a project but might not show how. Going over the official documentation for MongoDB and Dash to learn how to leverage those tools to improve my artifact.
This enhancement met many of the course outcomes planned. As I made updates to the artifact, I pushed it to GitHub and gave them descriptive commit messages to be precise in the changes I have made. Allowing anyone to see the changes I made and to comment or add upon it. As stated above, I had to leverage existing ways of improving common or general algorithms by doing research on what is implemented by other developers or organizations. When the information was contradictory, I had to make a decision on what would suit the artifact and its needs. Using those resources along with reading through documentation from the tools used in the artifact I was able to deliver value and accomplish industry-specific goals of delivering speed, efficiency and flexibility for future enhancements.
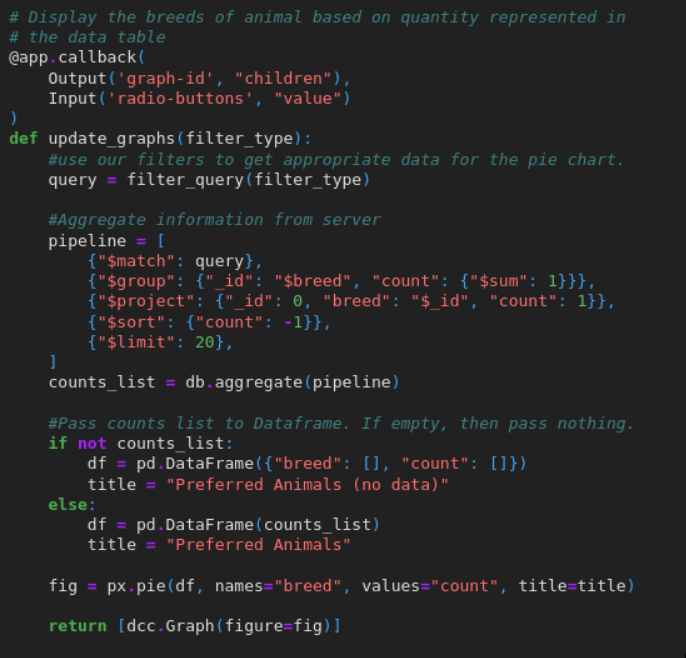
Databases
The artifact I selected for this enhancement in databases is “Grazioso Salvare Search-And-Rescue Dashboard” for the course CS-340 Client/Server Development. It is a dashboard created to aggregate data provided by nearby animal shelters in the Austin, TX area and display the information in a way for users to find suitable dogs for search and rescue training. I believe this artifact's inclusion aligns very well with my career goal alongside related industry-goals. Many organizations rely on databases to store and utilize data. It is important to be able to effectively navigate databases and optimize them to get every bit of performance. This becomes especially important when the data pool is very large and constant use of certain information is necessary. Previously, the credentials for the database were hardcoded into the code base. This leaves the program open to security risks. To mitigate this, the credentials were moved outside of the codebase into environment variables. The connection string also now uses SHA-256 as its secure authentication method. These changes help to protect the integrity of the database. Using a compound index, I was able to reduce query time by index scanning rather than scanning the entire documentation.

This is important especially as the database grows. By expanding the read function of the Python CRUD file, I was able to make it much more flexible to be used across different parts of code.
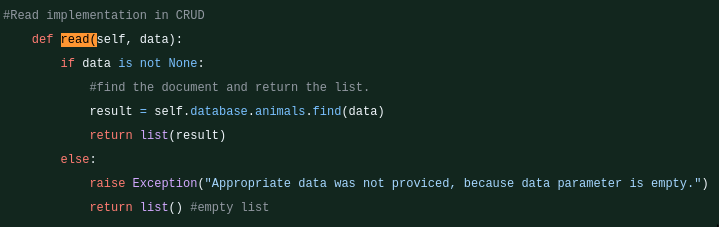
Another enhancement made was to reduce client-side strain to MongoDB using an aggregation pipeline. In this particular case, the pie-chart now offloads the work to MongoDB’s optimized C++ engine, speeding up the visualization and reducing load on the server. A course outcome that I believe was specifically met through this enhancement was developing with a security mindset that anticipates adversarial exploits in software. By creating a secure connection to the database by adding SHA-256 to the URI string and by moving the hardcoded credentials of the database to an outside environment variable, I have mitigated design flaws and enhanced the security of the data and resources of this artifact. The biggest challenge for me was expanding my knowledge of databases. I have only ever used databases for simple and small tasks so I did not have deeper knowledge on what goes on underneath the hood. This enhancement led me to go through some of the documentation provided by MongoDB to see what I could utilize and what is possible.
Security
By following the DevSecOps cycle, an individual or team of programs integrate security into every part of the development life cycle. For the "Grazioso Salvare" artifact, I have removed hardcoded credentials for the database and moved them into an environment variable that is not visible nor accessible to users. Aligns with the principle of least privilege.
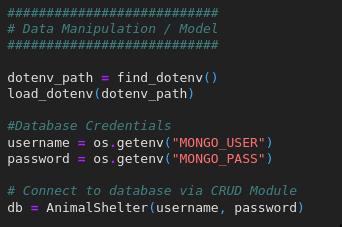
For connecting to the database with proper user authentication I used SCRAM-SHA-256 authentication for the MongoDB URI. This enforces encrypted authentication between the dashboard and MongoDB.

When dealing with conditional code blocks, it is important to have default cases to use as a way to mitigate any unintended behavior. This way the program can fail gracefully in predictable ways without suddenly crashing. This security enhancement can also help handle invalid inputs or database issues through error messages.